
こんにちは、Mathematica歴3年の筆者です。
当記事では超初心者向けにMathematicaの使い方をわかりやすく解説しています。
前回の記事では「乱数シミュレーション」について解説しました。
今回の記事では「機械学習」について学んでいきたいと思います。
機械学習とは、機械を使用して大量のデータの背景にあるパターンを自動で発見・学習するデータ分析手法です。
当記事では、「株価の予測」を題材にして、Mathematicaで機械学習を実装する方法を解説します。
具体的には、まずインターネット経由で株価のデータを取得し、Mathematicaに読み込む方法を解説します。
そして、機械学習で有名なアルゴリズムである「線形回帰」、「ニューラルネットワーク」、「ランダムフォレスト」を使用して株価の予測を行います。
それでは今回もよろしくお願いいたします。
1, データの取得
まずは解析する株価データがないと始まらないので、インターネットから株価データの取得を行います。
このサイトから株価のデータを取得します。
解析する銘柄はなんでも良いのですが、適当に「1305」にしてみます。
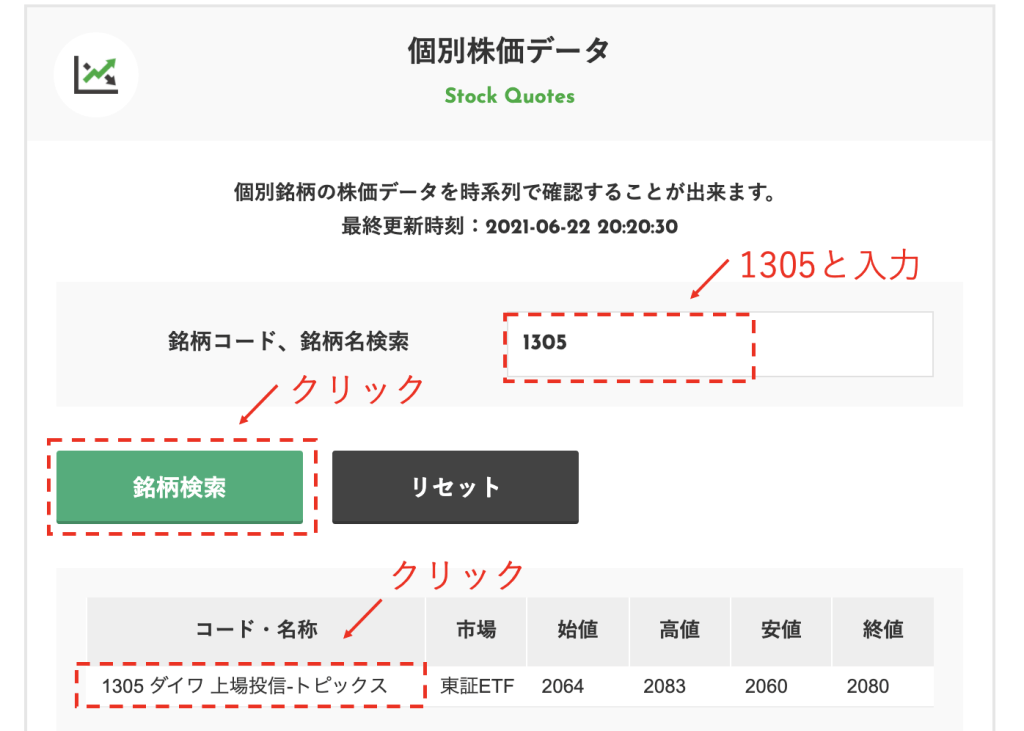
下図の「銘柄コード、銘柄名検索」のところに「1305」と入力して「銘柄検索」をクリックしてください。
すると「1305 ダイワ 上場投信-トピックス」と出てくるので、そいつをクリックしてください。
試しに2010年の株価データを取得してみましょう。
下図画面で「2010」をクリックして、「CSVデータダウンロードページへ」をクリックして下さい。

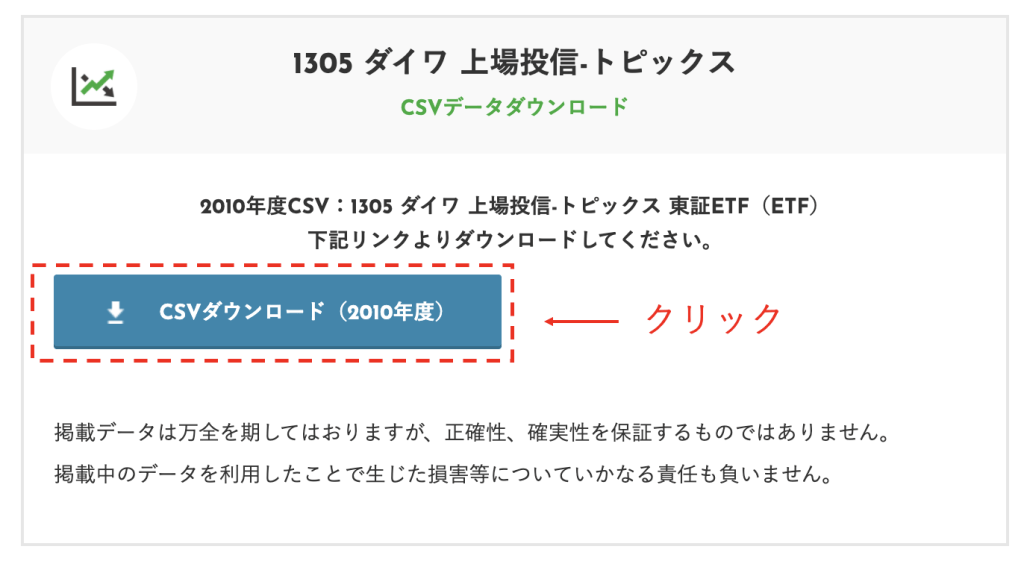
下図のような画面が表示されるので「CSVダウンロード(2010年度)」をクリックして下さい。
すると、パソコンのどこか(おそらくダウンロードフォルダ)に株価データがダウンロードされます。
同様の操作で、2010年から2015年までの株価データをダウンロードして下さい。
2, データの整形
続いて、ダウンロードした株価データを機械学習させるのに適した形に「整形」します。
「機械学習に適した形とはなんぞや?」と言う疑問をお持ちかと思います。
最終的にMathematicaで機械学習を行う際に、関数「Predict」を使用します。
したがって、機械学習に適した形とは「Predict」の引数として使える形ということです。
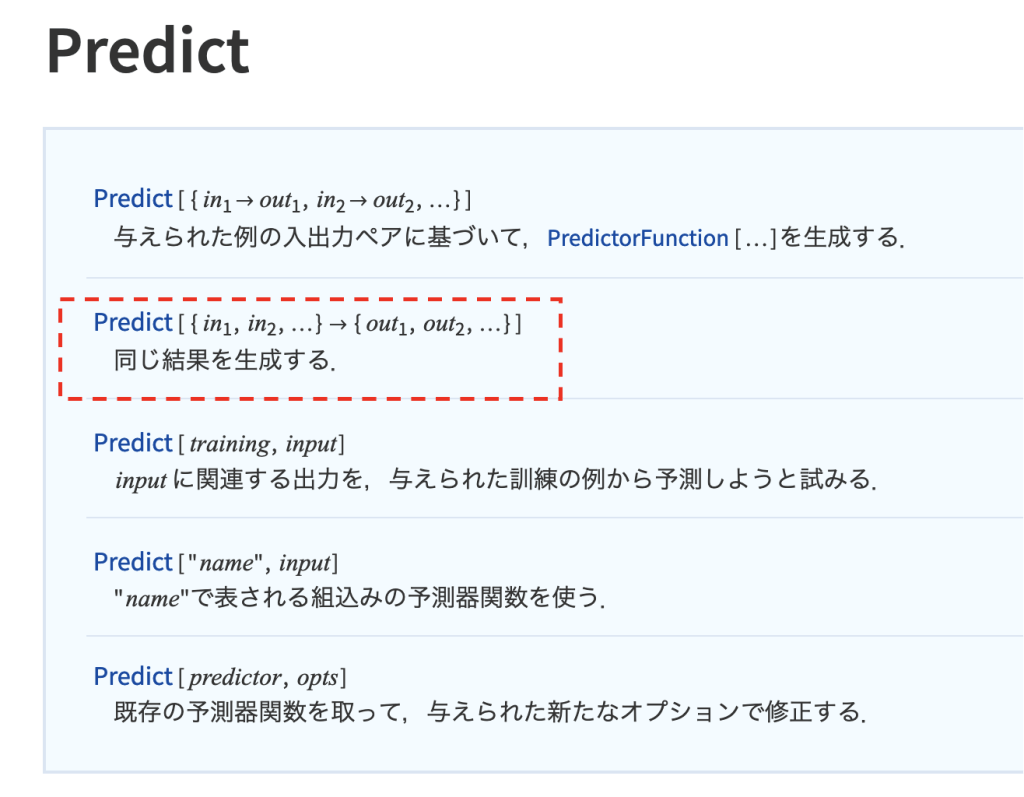
公式サイトをみると、「Predict」の引数として「{in1,in2,,,,,} -> {out1, out2,,,,}」という形が使えるようです。
この「Predict」の引数の「in」は説明変数、「out」は目的変数と呼ばれるものです。
説明変数および目的変数とは何かについて説明いたします。
競馬で例えると、前走の着順や体重、調教師のコメントなど着順の予測の元になるデータが説明変数で、実際の着順が目的変数です。
機械学習では、説明変数を入力して目的変数を出力します。
そして、機械学習では何を説明変数および目的変数とするかで予測の精度が大きく変わるため、説明変数および目的変数の選択は非常に重要です。
さて、今回の株価の予測では何を説明変数と目的変数とすれば良いのでしょうか?
答えは私もわかりません。株価の予測は非常に難しい問題として知られており、世界的にも良い予測方法が確立されていないのが現状です。
ひとまず、直近7日間の株価の動きを説明変数にして、次の日の株価の動きを目的変数としてみましょう。
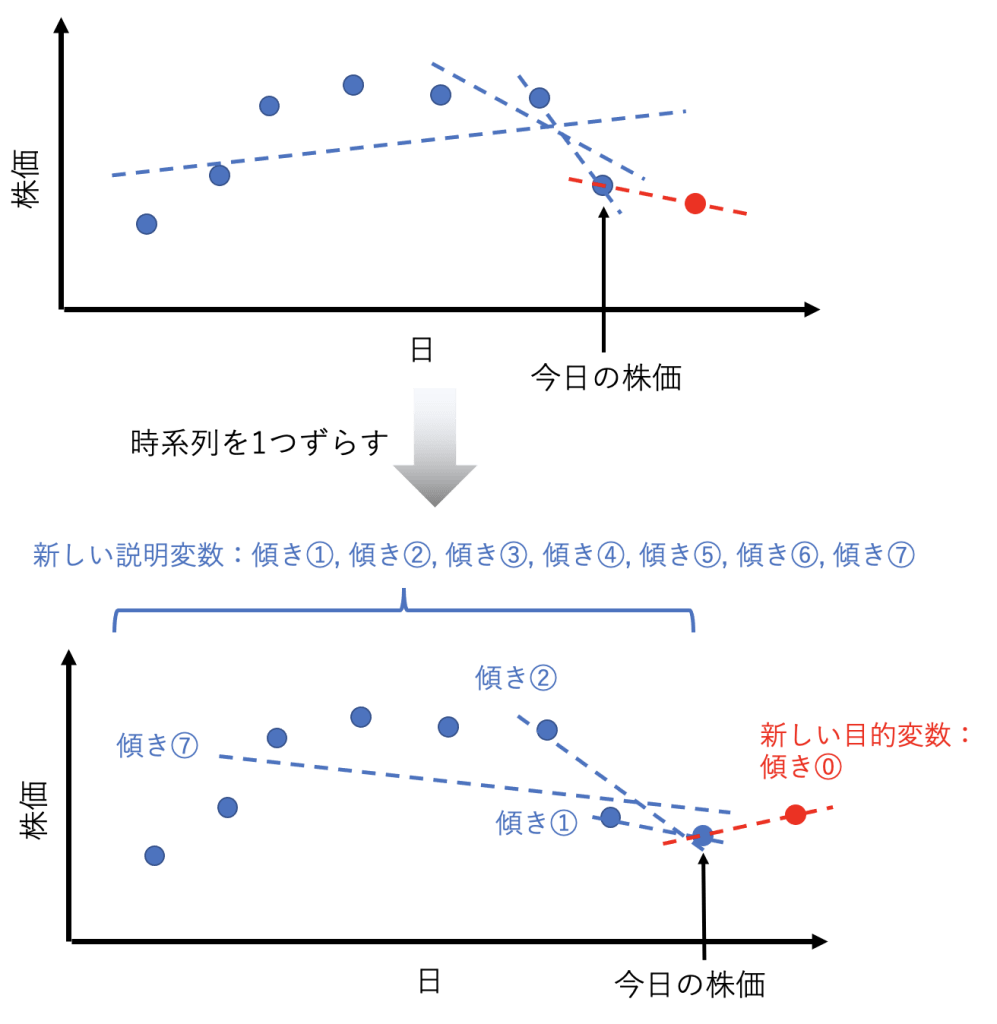
図で説明しますと以下の通りです。
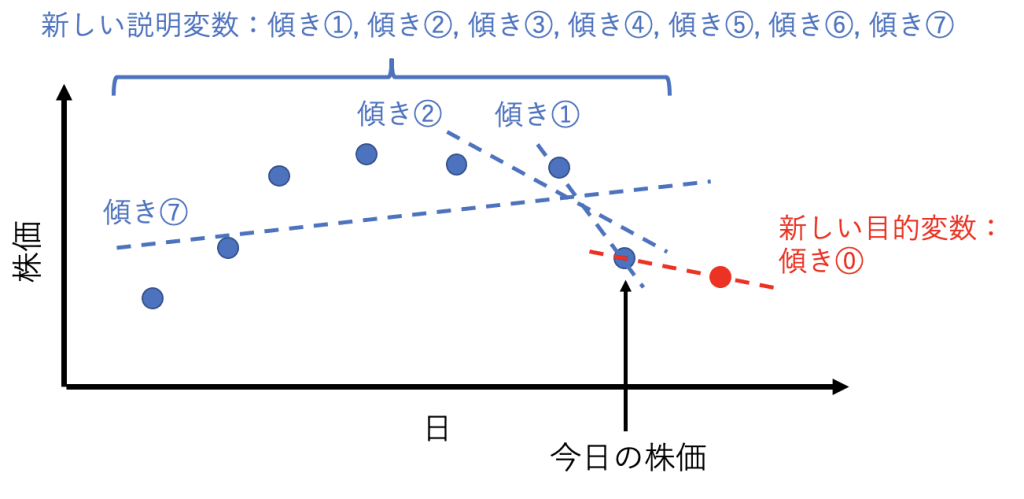
目的変数は上図赤点と直近の青点を結ぶ直線の傾きです。この赤点と直近の青点を結ぶ直線の傾きは、実際の世界では明日の株価が上がるか下がるかの予測に対応しています。
説明変数は7個あって、1つ目が昨日の株価と今日の株価の傾き、2つ目が一昨日と昨日と今日の株価の傾き、、、、、といった具合です。これらは、短期や長期で株価が上がり気味なのか下がり気味なのかを反映した値になります。
以上の目的変数と説明変数を、「Predict」の引数に適した「{in1,in2,,,,,} -> {out1, out2,,,,}」の形に整形することが目標です。
つまり、「in1」に「{傾き①, 傾き②・・・傾き⑦}」を指定し、「out1」に「傾き⓪」を指定するようにデータを整形しましょう。
ちなみに、「in2」および「out2」には、下図のように時系列を1つずらしたデータを使えば良いです。
整形後の形がわかったところで、いよいよデータを整形していきましょう。
最初に先程インターネットから取得した株価データをMathematica上に読み込む必要があります。データをMathematica上に読み込む関数は「Import」です。
「Import」の引数には株価データファイルのパス名を文字列型で指定してください。パス名の調べ方はwindowsとmacで異なります。
windowsの場合は、「Shift」を押しながらファイルを右クリックして「パスのコピー」をクリックするとパス名をコピーできます。
macの場合は、「option」を押しながらファイルを右クリックして「◯◯◯◯のパス名をコピー」をクリックするとパス名をコピーできます。
コピーしたパス名を「Import」の引数にペーストする際には、ダブルクォーテーション「”」で挟まれているか確認して下さい。
ダブルクォーテーション「”」で挟まれていない場合、「Import」の引数が文字列型と認識されないためエラーとなります。
試しに「2010年」のデータを「Import」して中身を確認してみて下さい。
以下のような中身になっていれば成功です。
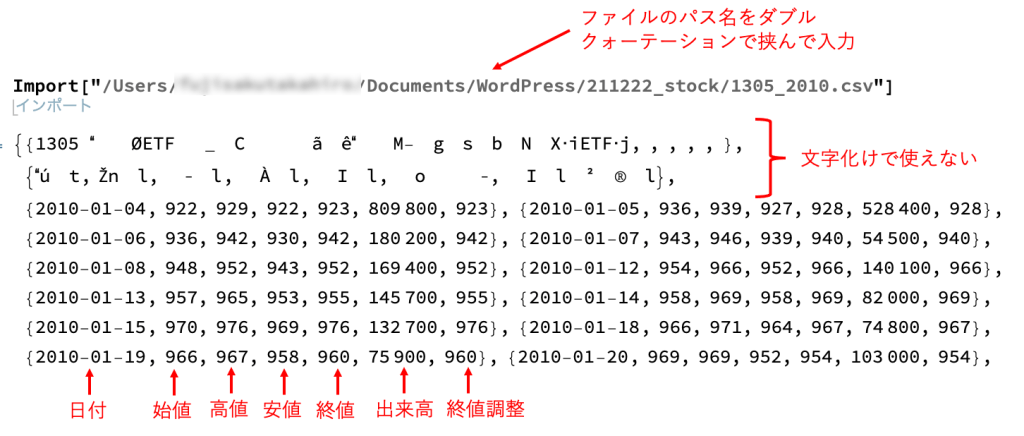
パス名はご自身のものを入力して下さい。
最初の2行は文字化けして使えないデータが入っていますね、、、こいつらは後で「Drop」関数を使用して取り除きます。
使うデータの中身には「日付」や「始値」、「高値」などが入っていますね。とりあえず今回は「始値」を使用していきましょう。
実際に「Import」したデータから「始値」を取り出してデータを再構成してみましょう。
ちなみに始値とは、取引が開始される時間での株価です
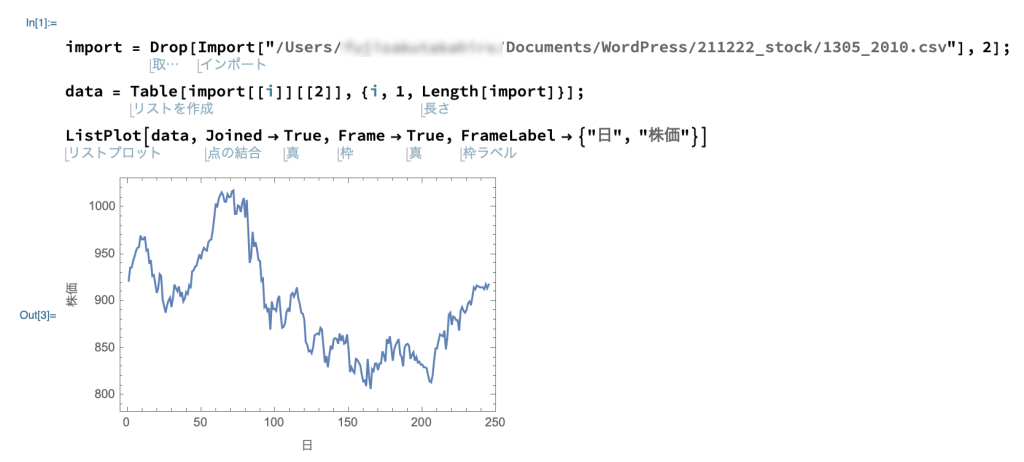
筆者の作ったコードは以下です。「data」の中に「始値」の時系列データが格納されています。

ちなみに始値の時系列データである「data」を折線グラフ表示で表示すると以下のようになります。
上図のデータを使用して、「Predict」の引数に適した「{in1,in2,,,,,} -> {out1, out2,,,,}」の形を作っていきましょう。
筆者の作ったコードは以下の通りです。

コピペ用は以下の通りです。
2行目のパス名はご自身のものに書き換えて下さい。
また7行目の「days」に対して、1つの説明変数が何日分を含むかを指定することができます。
上記コードでは、始値の時系列データから順番にデータを取り出して、それぞれ「y = ax + b」でフィッティングして傾き「a」を算出し、説明変数のリスト「paramList」に格納していきます。
「paramList」の中身を確認してみましょう。
以下のように、「paramList」は長さ7のリストが1つの要素であるリストであることが確認できます。

同時に対応する傾きを目的変数のリストに格納しています。中身は以下の通りです。
以上でデータの整形は完了です。
3, 整形したデータを機械学習
続いて、整形したデータを使用して機械学習を実装してみましょう。
といっても「Predict」の引数に整形したデータを指定するだけです。
コードは以下の通りです。
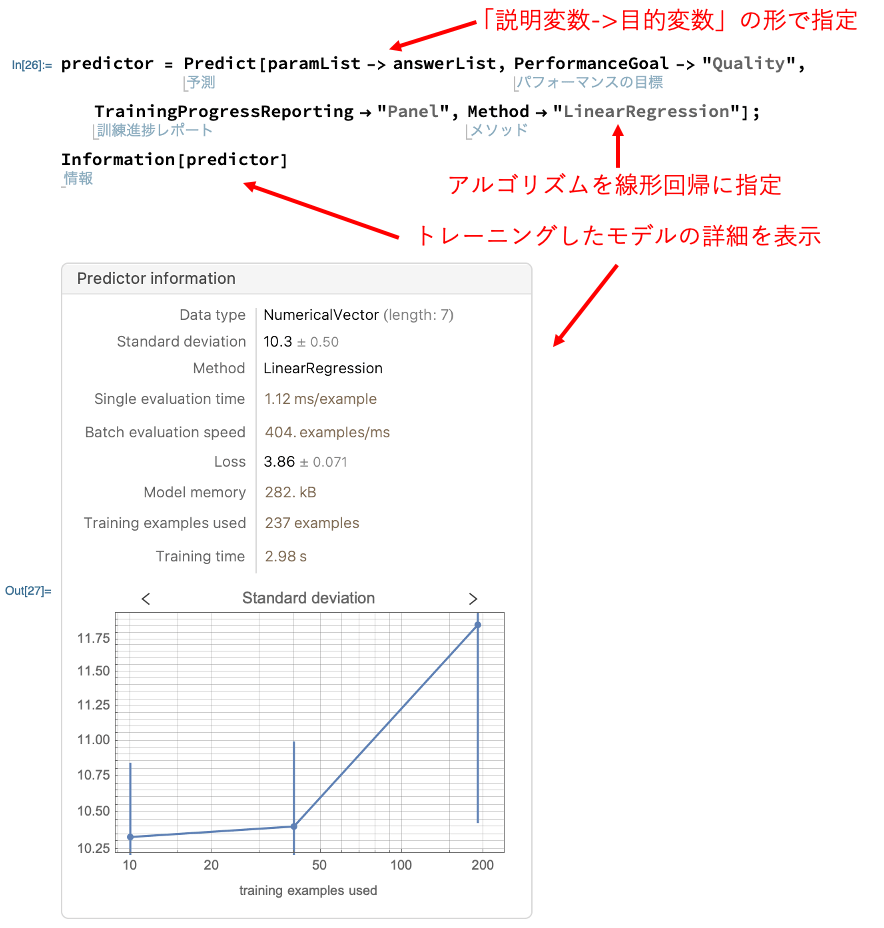
「Predict」の引数に整形したデータを「説明変数->目的変数」の形で指定しています。
その他の引数は省略可能ですが、今回は以下のように指定しました。
「PerformanceGoal」は精度を最大化するために「Quality」を指定しました。
「TrainingProgressReporting」を「Panel」を指定することで、機械学習の進捗状況をリアルタイムで表示するようにしました。
「Method」は線形回帰である「LinearRegression」を指定しました。
最後の「Information」でトレーニングしたモデルの詳細を表示しています。
さて、トレーニングしたモデルがきちんと予測できているのかを確認するために、予測値と実測値のプロットをしてみましょう。
予測がきちんとできている場合、予測値と実測値のプロットは直線になります。
また、予測の精度を表す決定係数R^2も計算しましょう。
式は以下の通りです。
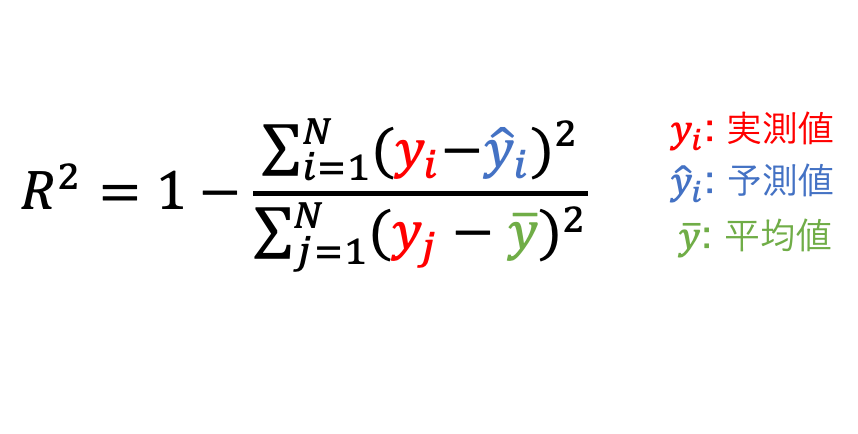
予測が完璧な場合、決定係数は1になります。
一方、予測の精度が悪すぎると決定係数はマイナスの値になります。
予測値と実測値のプロットおよび決定係数を計算するコードは以下の通りです。
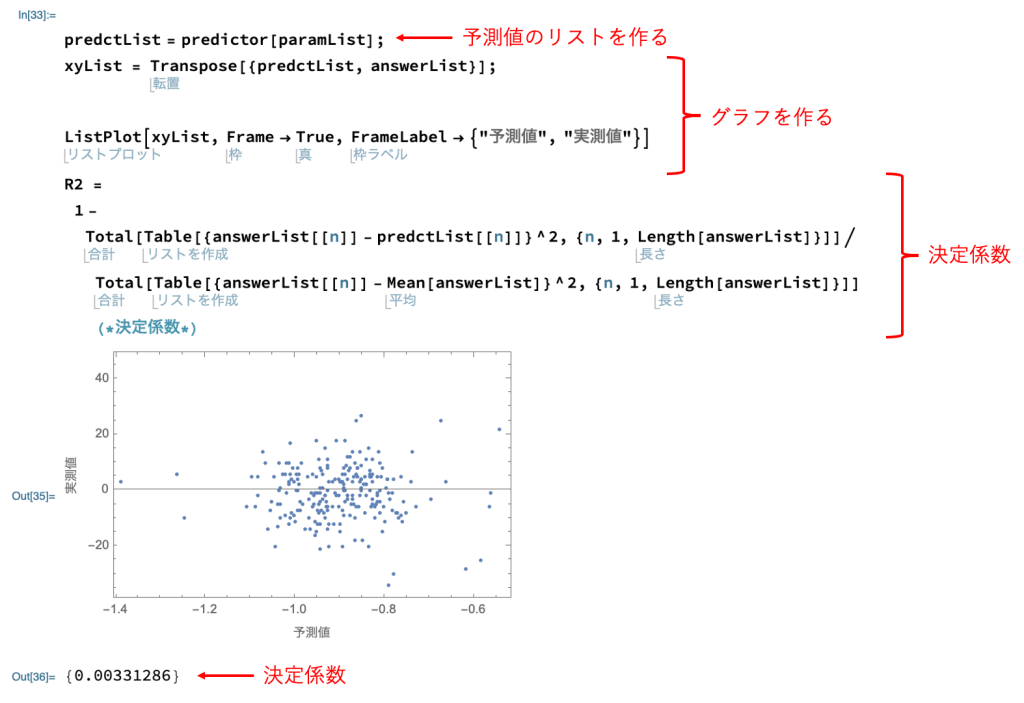
コピペ用は以下の通りです。
上図のグラフは全く直線になっていないですね、、、、、決定係数も0.0033と非常に低い値です。
ちなみに、決定係数は0.5以上あるとそこそこ良いモデルであると一般的に言われています。
今回の条件ではうまく予測ができないことがわかりました。
そこで、アルゴリズムを「ニューラルネットワーク」または「ランダムフォレスト」に変えてみましょう。
前回と同じコードで、「Predict」の「Method」を「NeuralNetwork」または「RandomForest」に変更してみて下さい。
予測値と実測値のプロットは以下の通りです。
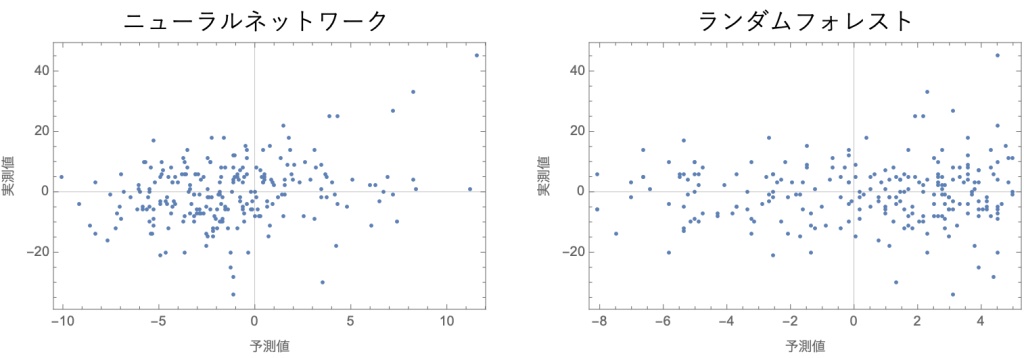
どちらも直線になっていませんね、、、、
やはり株価の予測は難しいということがわかりました。
最後に、トレーニングに使用するデータ数を増やすことを試してみましょう。
これでは2010年のデータのみを使用してきましたが、最初にダウンロードした2011〜2015のデータも使用しましょう。
また、今まではトレーニングとテストに同じデータを使用していましたが、今回はきちんと分けます。
コードは以下の通りです。


コピペ用は以下です。
上記時コードを使用する際は、8行目のパス名をご自身のパス名に書き換えて下さい。
1〜10行目で、2010年から2015年の株価データをFor構文を使用してまとめて読み込んでいます。
11行目で、「Flatten」を使用してリストの次元を1下げて、2010年から2015年の株価データをまとめています。
12行目で、「始値」を取り出しています。
13〜27行目で、先程と同様にフィッティングで傾きを算出して、説明変数と目的変数を生成しています。
29〜45行目で、トレーニングとテスト用にデータを分割しています。
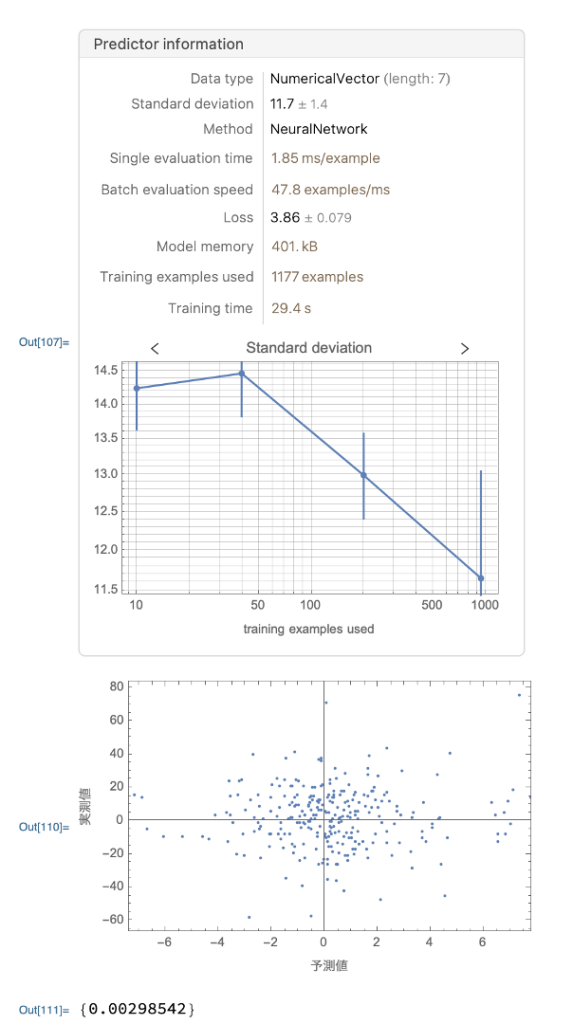
47〜51行目で、てレーニング用データをもとにニューラルネットワークによってモデルを構築しています。
53〜61行目で予測値と実測値のグラフと決定係数を出力しています。
以上がコードの説明になります。
そして結果は、、、、、グラフが直線ではなく、決定係数も0.00298と小さい値であることから、うまく予測できていないことがわかります。
コードに問題はないと思われるので、説明変数と目的変数を再設定する必要があると思われます。
ですが、以上の流れでMathematicaで機械学習を実装することができます。
ぜひ他の問題に機械学習を応用する際に上記コードを参考にして下さい。
今回は以上になります。
また全7回の「Mathematicaの使い方講座」も今回で終了となります。
ここまでの内容を理解できればMathematicaを使用してあらゆるコードを自作できると思います。
最後までお付き合いいただきありがとうございました。