
競馬ファンなら自作のAIで勝ち馬を予測してみたいと思いますよね。
この記事では、Pythonを用いたnetkeibaのスクレイピング方法についてわかりやすく解説します。
スクレイピングとはインターネット上のデータを自動で取得する行為です。
スクレイピングの方法をPython初心者向けにかなり詳しく解説していますので、上級者には冗長な内容かもしれません。
また、競馬データの解析ではPythonのプログラミングスキルが必須になります。
Pythonの基本が完全には身についていない方は、以下の本で勉強するのがおすすめです。

特に、Pythonを使って機械学習の理論について学びたい方はこちらの本がおすすめです。

ライブラリのインストール
PythonのライブラリはrequestsとBeautifulSoupを使用します。
最初にこれらのライブラリをインストールします。
windowsの場合はコマンドプロンプト、macの場合はターミナルに以下のように入力してEnterを押します。
pip3 install requests
以下のように表示されれば成功です。
同様の操作で必要な下記ライブラリもインストールしてください。
pip3 install beautifulsoup4
HTMLについて
実際にnetkeibaからデータを抽出してみましょう。
下記のサイトをGoogle Chromeで開いて下さい。
https://db.netkeiba.com/race/202003010302
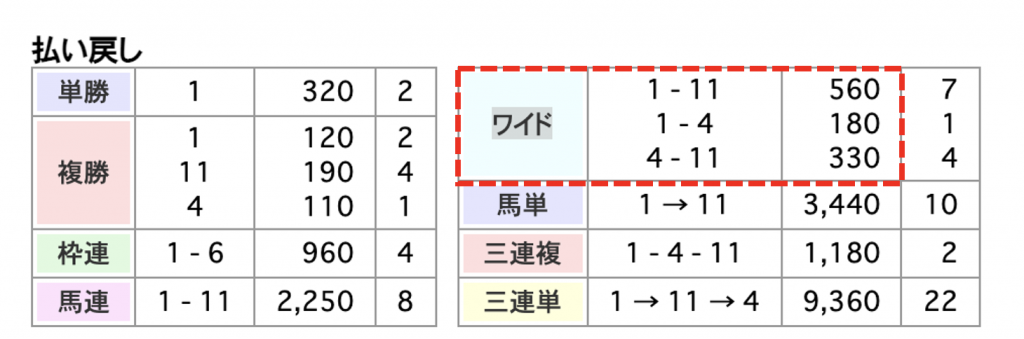
試しに「ワイドの払い戻し」を抽出してみましょう。
サイトの下の方に払い戻し一覧があります。
この中から下図の赤線で囲ったワイドの払い戻し情報をPythonを使って取り出します。
windows場合は「control + shift + i」、macの場合は「command + option + i」を押して下さい。すると、以下のような画面が立ち上がります。
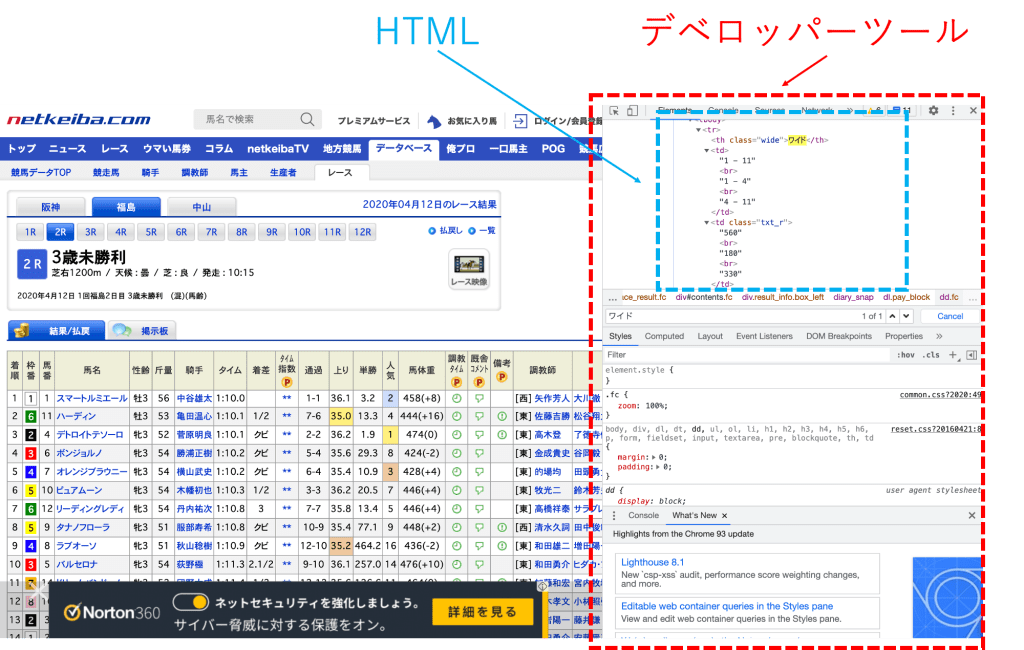
これはデベロッパーツールと呼ばれるものです。
デベロッパーツールを開くことで、サイトの中身に関する情報が詰まったHTMLを見ることができます。
HTML上で「command + f」を押すと、以下のような検索バーが出でくるので、ここに「ワイド」と入力してEnterを押します。
すると下図のようにワイドに関するHTMLを見ることができます。
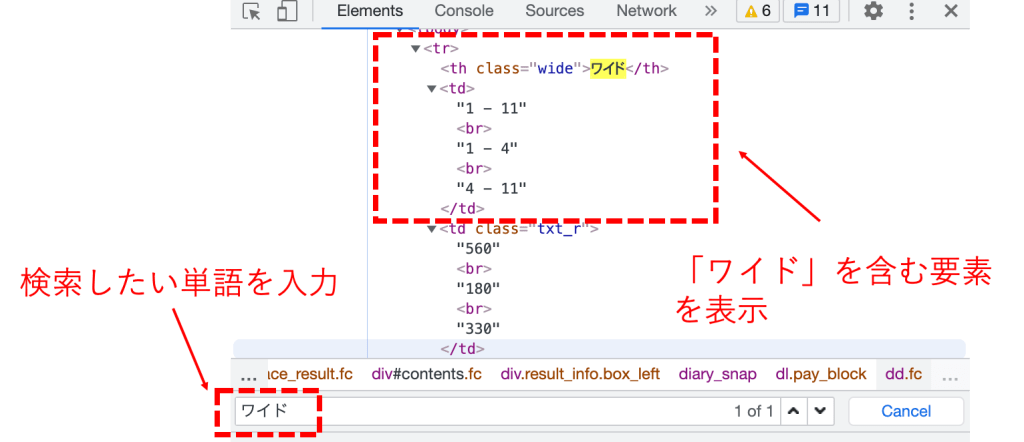
この「1-11」ですとか、「”560″」といった情報をPythonで取得していきます。
ここでHTMLの基礎知識について触れておきましょう。
HTMLとはサイトを文字で記述したものです。
重要な点は、HTMLは「要素」で構成されており、それぞれの要素は「属性」を含んでいると言うことです。
先程の例で言うと、要素と属性は下図のように対応しています。
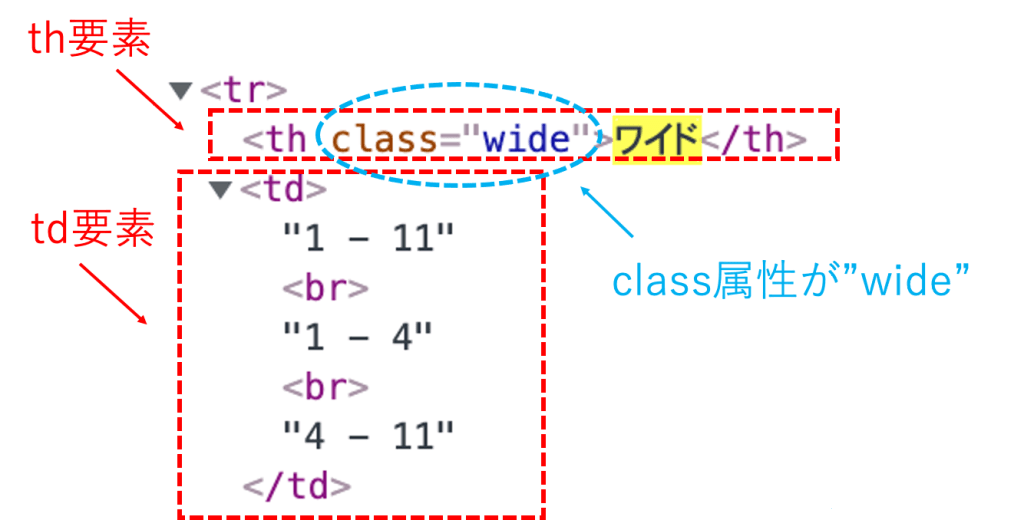
要素は「<th>」のような開始タグと「</th>」のような終了タグで囲まれています。またこの場合の要素名は「th」となります。
属性は開始タグの中に「class = “wide”」のように記述されます。この場合、「class属性が”wide”」となります。
Pythonでは要素や属性をもとに情報を抽出します。
例えば先程の「”560″」を取得することを考えてみましょう。下図のように要素名が「td」でclass属性が「”txt_r”」の要素を取得すればよいということになります。

具体的なコードは下記です。
Pythonを開いてFileからNew Fileを生成します。
エディタが開くので、上記サンプルコードをコピペして下さい。
「Run」の中の「Run Module」を押すことでコードを実行します。
先程のコードでは、「soup.find_all(“td”,class_=’txt_r’)」の部分で、要素名が「td」でclass属性が「”txt_r”」の要素を取得しています。
つまり、「find_all」の第1引数に要素名を指定し、第2引数に属性を指定することで、HTMLから要素名と属性が一致した要素を全て抽出してくれます。
実行すると以下のような結果になります。
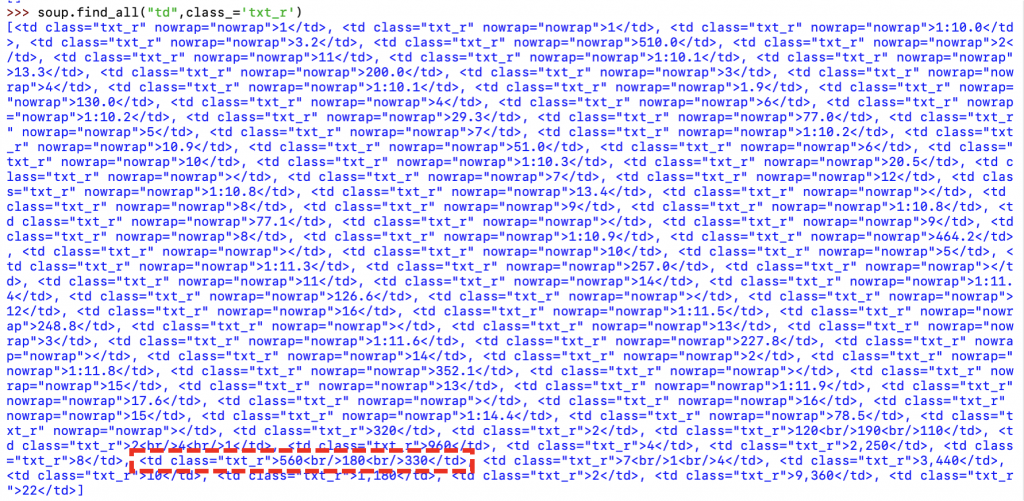
「soup.find_all(“td”,class_=’txt_r’)」では、要素名が「td」でclass属性が「”txt_r”」の要素が全て抽出するため、たくさんの候補が表示されています。
そして、上図の赤で囲ったように確かに「”560″」を抽出できています。
ですが、これだと流石に候補が多すぎるので、別の要素名や属性で抽出したいところです。
ワイド周辺の要素を見てみると、下図赤線で示すような”良さげ”な要素がありました。
(払い戻しという単語はサイト内それほど使われていなさそうな単語なので、候補を少なくできそうという意味での”良さげ”です)
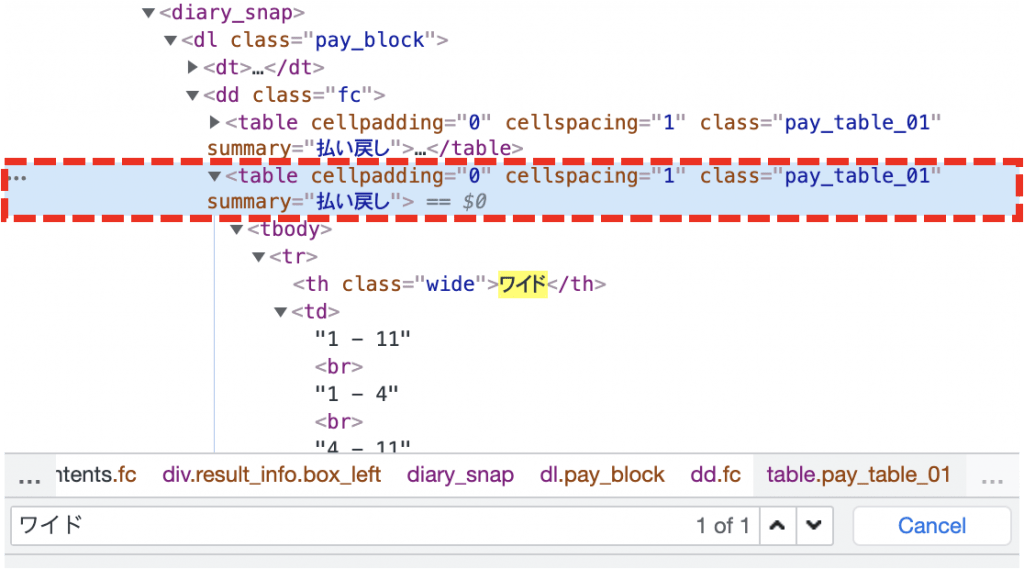
上図の赤で囲った部分は、要素名が「table」でsammary属性が「”払い戻し” 」の要素です。これをPythonでを抽出しましょう。
この要素名が「table」でsammary属性が「”払い戻し” 」の要素を抽出するコードは「soup.find_all(“table”,summary=’払い戻し’)」です。実行すると以下のように出力されます。

先ほどよりもわかりやすく抽出できていますね。
ひとまず、インターネット上からPythonに情報を取り出す流れが掴めたでしょうか?
次から、さらに詳しく情報を取り出していきます。
欲しい情報をスクレイピングする
先程、ざっくりとワイドの払い戻し情報を含んだデータを取得できました。ここからさらに情報を選別して「ワイドの払い戻し」を取得してみましょう。
まず初めに、Pythonでは型を意識することが重要であるということを強調しておきます。
今回で言うと、「soup.find_all()」を使うと「bs4.element.ResultSet」という型でデータを返すということを覚えておいてください。
この「bs4.element.ResultSet」とは「bs4.element.Tag」型を要素とするリストみたいなイメージです。
「bs4.element.ResultSet」と「bs4.element.Tag」は型が異なるので、当然使えるメソッドも異なります。
「bs4.element.ResultSet」と「bs4.element.Tag」の違いを意識してコードを書かないとエラーを吐きまくるので注意しましょう。
さて、いよいよワイドの払い戻しを抽出します
先述の「soup.find_all(“table”,summary=’払い戻し’)」は「bs4.element.ResultSet」型です。
これをリストと同じような操作で、「soup.find_all(“table”,summary=’払い戻し’)[1]」とすると「bs4.element.Tag」型を返します。
そして「bs4.element.Tag」型に対しては「.contents」というメソッドを使用可能で、「bs4.element.Tag」型を「list」型に変換できます。
この変換後のlistの要素が「bs4.element.Tag」型になっていて、、、、といった具合に「bs4.element.Tag」型と「list」型 を行き来しながら欲しいデータに辿り着きましょう。
さて、今回の目的はワイドの払い戻しを取得することでした。実際にやってみてください。といっても難しいと思いますので、答えは以下です。

ポイントは「型を意識すること」に尽きます。型の確認は「type()」を使います。
このような流れで欲しい情報を抽出します。
csvファイルに保存する
ここまでで欲しい情報をインターネット上から取り出す方法を解説しました。
次に、取得した情報を使いやすい形で保存してみましょう。
まず、ワイドだけでは味気ないので、単勝や複勝、三連単といった払い戻しも抽出してみましょう。
再びPythonを開いてFileからNew Fileを生成します。
エディタが開くので、そこに下記のコードをコピペして下さい。
defの部分で関数を作成していますが、コードを短くする以外特に効果はないです。
下記コードでは、「beautifulSoup」で取ってきた情報を「contents」を用いてさらに抽出して、「payBackList」に保存していきます。
「Run」の中の「Run Module」を押すことでコードを実行します。下図のようにIDLE Shellが立ち上がります。
うまくいったかを確認してみましょう。下図のように「payBackList」と打ち込んでEnterを押します。以下のように表示されれば成功です。
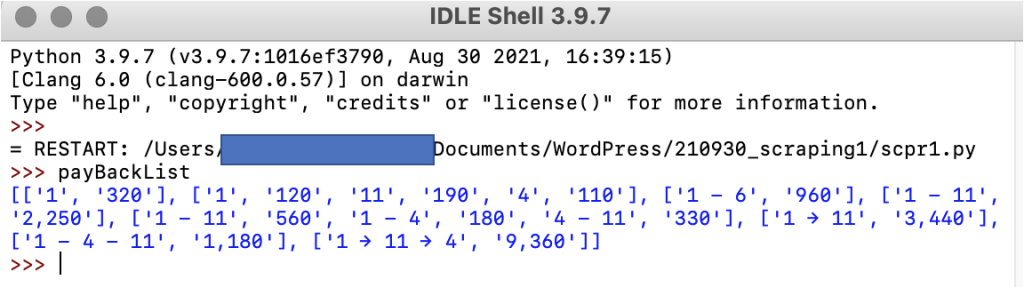
「payBackList」の中に馬番と払い戻し情報が規則的に格納されてますね。
ついでに馬名や騎手の情報もまとめてみましょう。筆者が作成したコードを後で載せます。
欲しい情報を取り終えたら、csvファイルに保存してみましょう。
まず、csvファイルとして保存するためにライブラリ「csv」をインポートします。
「csv」はデフォルトで入っているライブラリであるため、pip3でインストールする必要はありません。
以下のコードを実行すると、指定した場所に競馬データをcsvファイルとして保存します。
ただし、101行目のwith open()の第1引数の部分にご自身の保存先のパスとファイル名を記述してください。
パス名の調べ方はwindowsとmacで異なります。windowsの場合は、「Shift」を押しながらパス名を調べたいファイルを右クリックして「パスのコピー」をクリックするとパス名をコピーできます。macの場合は、「option」を押しながらパス名を調べたいファイルを右クリックして「◯◯◯◯のパス名をコピー」をクリックするとパス名をコピーできます。
(上記コードは2022年1月5日時点で有効であることを確認しました。)
うまくいっていればご自身でパスを設定した場所にcsvファイルが出力されます。
csvファイルを読み込む
先程保存したcsvファイルを読み込んでみましょう。
csvファイルの読み込みにはpandasというライブラリを使用します。
いつも通り、ターミナルに「pip3 install pandas」と入力してインストールしましょう。
次に、下図のように「import pandas」と記述してEnterを押して下さい。
その後、下図のように「pandas.read_csv(‘/XXXX/XXX.csv’,encoding=”SHIFT-JIS”,header=None)」と入力してEnterを押します。
ここで、「’/XXXX/XXX.csv’」の部分にはご自身のパスとファイル名を記述してください。(先程csvを生成するときに使ったものをコピペでOKです。)
以下のように出力されれば成功です。

きちんと1レース分の競馬データを保存できていますね。
この操作を繰り返すことで競馬データを収集できます。
しかしながら、毎年開催されている約3000レースを毎回URLを書き直してスクレイピングするのは現実的ではないですよね、、、、
そこでfor構文を使うことで1年分のレース結果をまとめてスクレイピングする方がよさそうです。
1年分をまとめてスクレイピング
netkeibaの1年分のレース結果をスクレイピングするためには、netkeibaのURLの仕組みを理解する必要があります。
netkeibaではURLの最後に12桁の数字がついており、これが特定のレースに対応しています。
具体的には以下のような対応になっています。

最初の4つの数字が西暦、次の2つの数字が競馬場、次の2つの数字が第何回開催か、次の2つの数字が開催何日目か、最後の2つの数字が何レースかに対応しています。
特に競馬場と数字の対応は以下の通りです。
01:札幌、02:函館、03:福島、04:新潟、05:東京、06:中山、07:中京、08:京都、09:阪神、10:小倉
この数字をPythonのFor構文でループさせることで1年分のレースデータをまとめてスクレイピングします。
サンプルコードは以下になります。
上記コードは2022年1月5日時点で有効であることを確認しました。
上記コードの使い方を説明いたします。
まずPythonを起動して、FileからNew Fileでエディタを開いて、上記コードをコピペして下さい。
次に5行目の「#西暦を入力」の部分で西暦を指定してください。例えば「year = “2013”」とすると、2013年のレース結果をまとめて取得できます。
また150行目で保存先のパスを指定してください。サンプルのままですと、Usersの下に2020.csvが生成されます。
最後に「Run」から「Run Module」をクリックするとでコードを実行します。
28から36行目の「w、z、y、x」がそれぞれ、「競馬場、開催、日、レース」に対応しています。これらをfor構文で更新しています。
進捗を表示するために142行目で、第何回開催、何競馬場、何日目、何レース目をスクレイピングしたかを表示するように指定しています。
またコードの途中で「try」と「Except」が使用していますが、これはエラー対策に有効です。
筆者の環境ですと、2022年1月時点では上記コードでスクレイピングできますが、環境やバージョンの更新でバグが出るかもしれません。
その際はきちんと原因を突き止めて、「try、except」などを使いつつデバッグしてください。
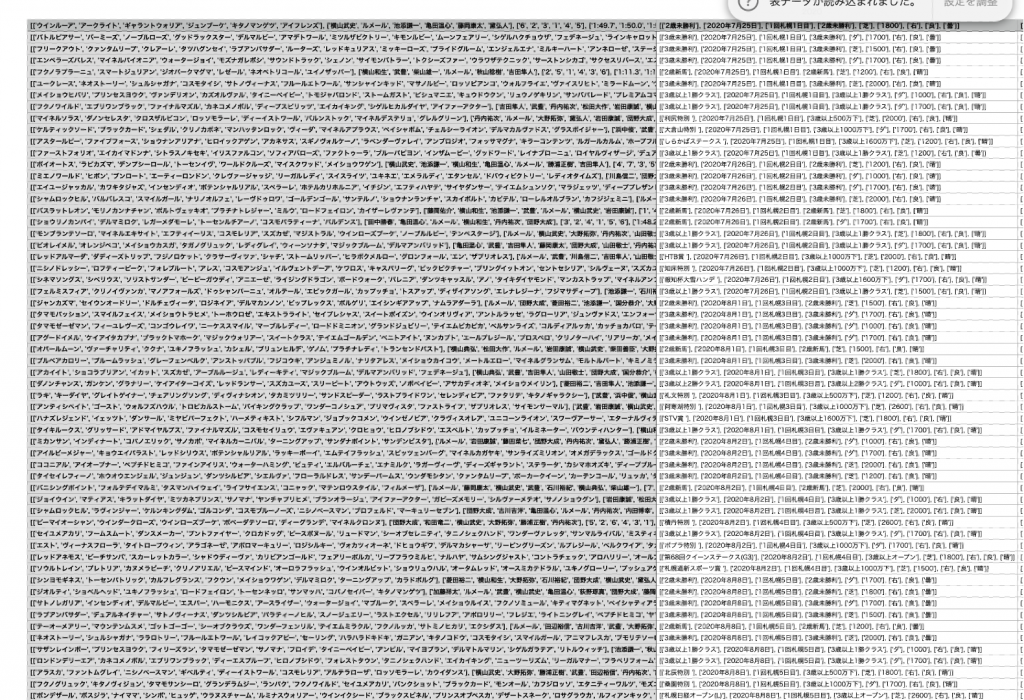
成功していたら、指定したパスにcsvファイルが出力されます。
試しにkeynoteなどでで開いてみてください、以下のようにデータが入っていれば成功です。
以上でnetkeibaからレース結果をスクレイピングする方法の解説を終了します。
長い間、お疲れ様でした。
2022年6月15日追記
上記コードでバグが出ると言う報告がありました。
2022年でしか機能することを確かめていませんが、以下のコードも試してみてください。
なお上記コードは中央競馬でのみ使用できます。
地方競馬をスクレイピングする方法はこちらの記事で解説しています。