
競馬ファンなら、自作のAIで勝ち馬を予測してみたいと思いますよね。
この記事ではPythonを用いた競馬予想AIの作り方と回収率についてデータとソースコードを載せながら詳しく解説しています。
結論を記載しますと、2020年〜2021年のテストデータに対して
単勝回収率109%
複勝回収率113%
となりました。
早速作り方を解説していくのですが、具体的にやることを先にまとめておきます。
1、競馬データを取得する(前回の記事で解説)
2、競馬データを機械学習用に整形する
3、2005年から2015年のデータを使用して、機械学習する
4、2016年から2019年データを使用して、最適な買い方を探索する
5、2020年から2021年のデータを使用して、回収率を計算する。
それではやって行きましょう。
また、競馬データの解析ではPythonのプログラミングスキルが必須になります。
Pythonの基本が完全には身についていない方は、以下の本で勉強するのがおすすめです。

また、筆者は以下の本を使ってPythonを使った機械学習の理論を学びました。

データの整形
データを整形するためには元になるデータが必要です。
競馬のデータは前回の記事を参考にして取得して下さい。(netkeibaを元にしています。)
データの取得ができたら、機械学習を行うためにデータを整形して行きましょう。
サンプルコードは下記の通りです。めちゃくちゃ長いですね、、、、ですがご自身で設定いただく箇所は少ないのでご安心下さい。
こいつの使い方を解説していきます。
注意:上記コードは前回の記事で生成した競馬データに対してのみ使用可能です。
前回の記事で生成した1年分の競馬データを下図のように1つのフォルダの中に入れます。
またファイル名が「2013.csv」のような形になっていることを確認して下さい。
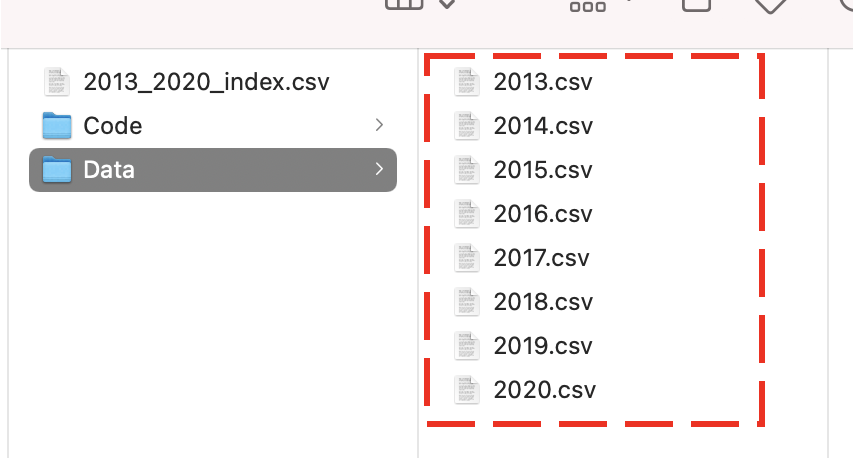
サンプルコードの4から5行目のyearStartとyearEndに、上図のcsvファイル名の最小値と最大値を入力して下さい。
上図の場合は「yearStart = 2013」、「yearEnd = 2020」になります。
続いてサンプルコード11行目のvar_pathに、上図のcsvファイルが入っているフォルダのパスを記述して下さい。
windowsの場合は、「Shift」を押しながらファイルを右クリックして「パスのコピー」をクリックするとパス名をコピーできます。
macの場合は、「option」を押しながらファイルを右クリックして「◯◯◯◯のパス名をコピー」をクリックするとパス名をコピーできます。
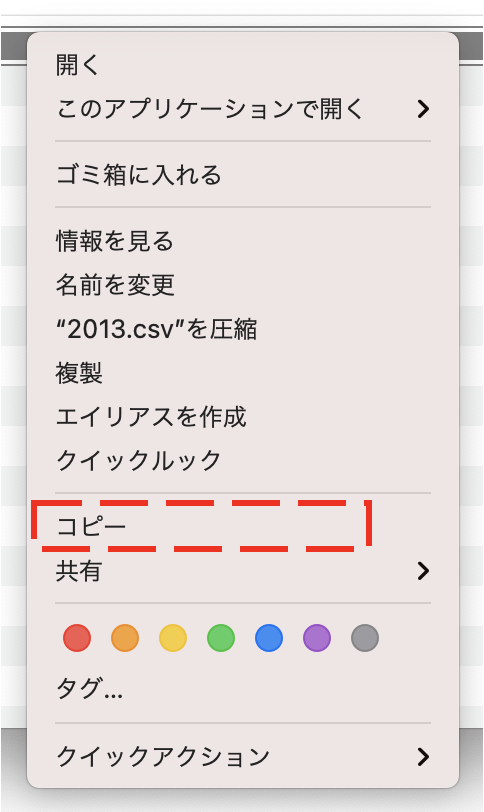
macで説明いたしますと例えば、2013.csvを右クリックすると下図のような画面が出ますが、ここでoptionキーを押すと「コピー」が「”2013.csv”のパス名をコピー」に変わリます。
これでパスをコピーできます。
先程コピーしたパス名をサンプルコード「”/Users/Documents/Python/Data/”」のところにコピペして、2013.csvの部分を消せばOKです。
サンプルコード11行目の「str(for_year) + “csv”」の部分が、forループ1回ごとに2013.csv→2014.csv→2015.csv、、、、といった具合に更新されていくので、2013.csvの部分は消してOKという訳です。
あとは特にご自身で設定してもらう部分はないため、いつも通りRunからRun Module等でコードを走らせればデータをいい感じに整形してくれます。
整形されたデータは「data」の中に格納されています。この「data」の中身を説明します。
整形後のデータの説明
「data」の中にはレース毎の情報が格納されています。
「data」の中身は「最近のレース→昔のレース」の順番で並んでいます。
dataの構造は下図のようになっています。
下図の2つの整数でdataの中身を取り出すことができます。

例えば 「data[0]」と入力すると一番最近(今回の場合、2020年12月末)のレース情報を見ることができます。
続いて「data[0][0]」と入力すると以下のように馬名のリストを取得できます。

続いて「data[0][1]」と入力すると以下のように騎手のリストを取得できます。

続いて「data[0][2]」と入力すると、、、、といった具合で調べていくと、レース情報と整数の対応は以下の通りになっていることがわかります。
前走の情報を追加するコードの説明
競馬の予測を行う上で大切なのが、前走、前々走などの過去の結果です。
そこで今回は前5走までのデータを追加してみます。
サンプルコードは以下の通りです。例えば、data[0]のレースで1着の「キティラ」の前5走を調べるとしましょう。
この場合、data[1]からdata[6000]までのレースの全ての馬名を調べて「キティラ」と一致するものを検索します。
そして、一致したもののレース番号と着順をリストに記録します(サンプルコード16〜17行目)。
前5走を調べるため、もしこのリストの長さが5を超えたら終了します(サンプルコード19〜20行目)。
そしてこの処理はだいぶ重いため、サンプルコード25〜26行目でcsvに保存しています。
筆者は2013年から2020年のデータを使用しているため、全レース数は約27000です。
使い方としましてはまず、2行目「getData」に何レース分を解析するのかを入力して下さい。
「なんで27000レース全部解析しないんや?」って疑問に思う方もいらっしゃるかと思います。
その答えは、例えば2013年1月のデータに対して「前5走までのデータを調べろ」と命令しても、2012年のデータがないので、「前5走までのデータ」は調べられないですよね。
言い換えると、最近のデータと昔のデータで解析条件が対等ではなくなってしまいます。これはデータ解析する上で良くないですよね。
そういった理由で、27000レースのうち最近20000レースを解析対象としました。
次に、3行目「pastRaces」で過去レース分遡るかを指定します。
「なんで過去レース全部遡らんのや?」って疑問に思う方もいらっしゃるかと思います。
これに関しては先程と同様に条件を揃えるためです。例えばレース番号0対して過去レース全部遡ると27000レース遡ります。
一方、レース番号20000の場合は7000しか遡りません。
このようにレース番号によって遡るレース数が対等ではなくなるため、過去レース分遡るかを指定しています。
そして、4行目「pastResults」で前何レースを参考にするのか指定して下さい。
最後に25行目のcsvファイルの保存先を指定して下さい。
保存したcsvファイルを読み込むコードは以下の通りです。ご自身で設定するのは2行目のパス名”/Users/Documents/Python/Data/2013_2020_index.csv”の部分だけです。
これを先程生成したcsvファイルのパス名に置き換えて下さい。
読み込んだcsvの情報は「pastIndex」の中に入っています。
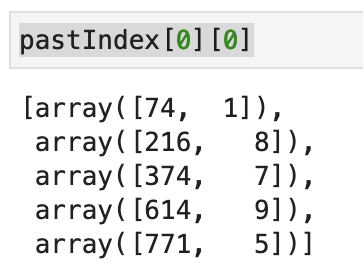
試しに「pastIndex[0][0]」を実行してみましょう。
「pastIndex[0][0]」の中には、下図のようにレース番号0で1着だった馬(キティラ)の前5走の情報が入っています。
見方としましては、前走はレース番号74で2着、前前走はレース番号216で9着、前前前走はレース番号374で8着といった具合です。
試しに検証してみます。「data[74][0]」を実行してみて下さい。下記のようにレース番号74の馬名が見れます。
確かに2着にキティラが記録されていますね。

以上でデータの整形は終了です。
整形したデータの機械学習
では、いよいよ機械学習をさせて行きましょう。
ここまでで2013年から2020年のデータを整形しました。
以下ではデータ数を増やすために2005年から2021年のデータを使用しています。
(2013年から2020年まででもOKです)
まず最初に、機械学習のアルゴリズムを決める必要があります。
結論としては「lightGBM」一択かと思います。
筆者も「ニューラルネットワーク」や「ランダムフォレスト」など様々なアルゴリズムを試してみたのですが、今回の機械学習はデータの数がかなり多いため、「ニューラルネットワーク」や「ランダムフォレスト」では学習に時間がかかりすぎてしまいました。
一方、「lightGBM」は大きいサイズのデータに対しても素早く学習できるため、今回の環境でも1〜5分程度で学習が完了しました。
それに「lightGBM」はデータを正規化や標準化する必要がないので、データの扱いが少し楽です。
以上の観点から、アルゴリズムは「lightGBM」で行きましょう。
次に説明変数と目的変数を設定する必要があります。
目的変数は機械学習の予測対象のことで、競馬の場合は着順や走破タイム、1着になる確率などになります。
今回は走破タイムを目的変数とします。
説明変数とは、前走の着順や通過、馬体重といった目的変数の予測の元になるパラメータです。
下記のコードでは説明変数に、
「馬番、年齢、性、体重、体重増減、斤量、クラス、出走馬数、距離、芝・ダ、過去5レース着順、過去5レースタイム、過去5レースの上がり、過去5レースの着差、過去5レースの間隔、過去5レースの距離変化、他の馬で平均タイム上位5頭の前走タイム、他の馬で平均タイム上位5頭の前走クラス」
を使用しています。
136行目で機械学習に回す割合を設定できます。
筆者は、2005〜2021年のデータを読み込んで、そのうちの0.6をトレーニングに使用したので、およそ2005〜2015年のデータがトレーニング用のデータになったわけです。
続いて、「lightGBM」のハイパーパラメータを最適化する必要があります。
「ハイパーパラメータとはなんぞや?」とお思いの方も多いかと思います。
ハイパーパラメータとは人間が手動で設定しなければならないパラメータです。
最適なハイパーパラメータの探索
①交差検証法とグリッドサーチの合わせ技
②Optunaを使った自動最適化
(交差検証法とグリッドサーチの詳細な説明はこの記事が参考になります。)
本サイトに記載しているコードでは、手動でハイパーパラメータを設定します。
サンプルコードは以下の通りです。
11行目から22行目までの部分で、ハイパーパラメータを入力します。
そして以下のコードを実行することによって、最適なハイパーパラメータを使用してlightGBMをトレーニングします。
そして、予測値と実際の値をプロットしてうまくいっているのかを確認しています。
さらに予測精度として決定係数を表示します。
決定係数が1に近づくほど予測の精度が高いと言えます。
ここまでのコードを全て走らせると以下のような結果が得られるかと思います。
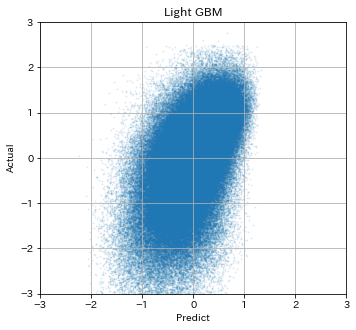
横軸が標準化した予測走破タイムで、縦軸が標準化した予測走破タイムです。
きちんと右肩上がりになっていれば予測がうまくいっています。
今回の説明変数とハイパーパラメータですと、決定係数は0.268となりました。
以上の手続きを繰り返して、決定係数が最大になるように説明変数とハイパーパラメータを調整してください。
最適な馬券の買い方の探索
以上で紹介したやり方などで最適なlightGBMのモデルを作ることが競馬AI作りのゴールになります。
何か良さげなモデルができたら、次は最適な馬券の買い方を探索して、実際の回収率を算出して見ましょう。
筆者は、機械学習によって予測された勝率からオッズを算出して、実際のオッズを予測オッズで割って回収率の期待値を算出し、回収率の期待値が100%を超える馬券を買うという方法を用いました。
毎レース100円購入する場合、
1年間に稼げる金額 = 回収率 x 購入点数 x 100
です。
そこで、筆者は上記のプロセスで作成したAlを使用して算出した期待値に対する回収資金のプロットを作って、期待値がいくらなら購入すべきなのかを実際のオッズ毎に単勝と複勝で調べました。
まずは単勝の場合です。
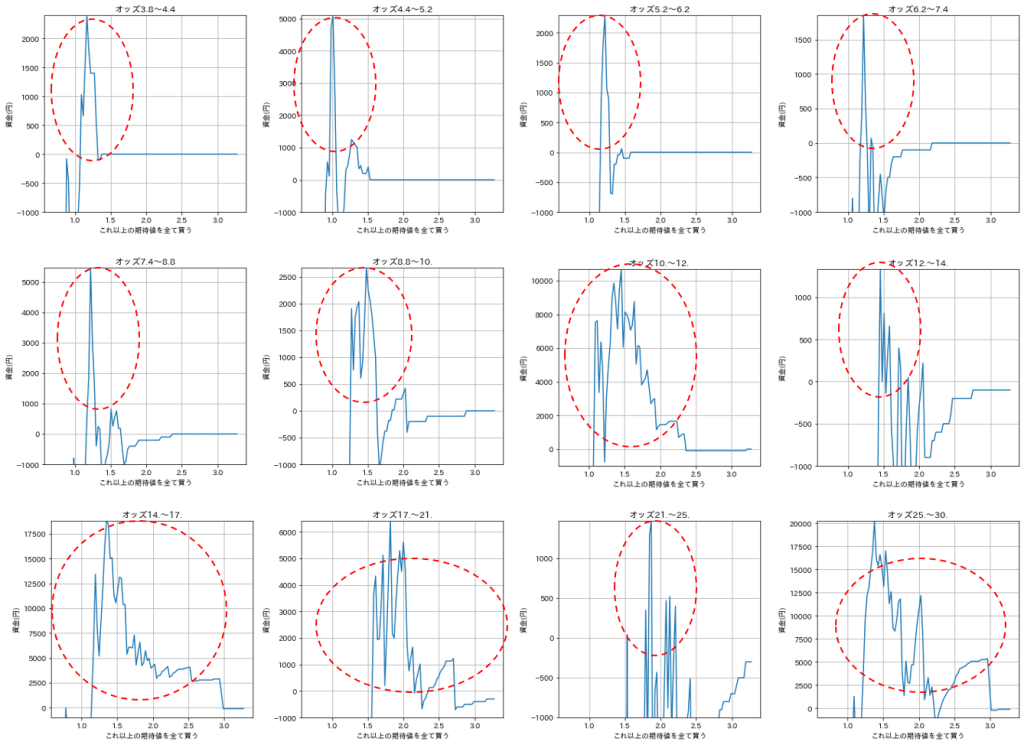
実際のオッズの範囲をグラフ上に表示し、縦軸に資金(=収支)、横軸に期待値をプロットしました。
このグラフを作るために使用したレース数は約28000レースであり、統計的にも十分であると思われます。
全体として期待値が1を超えていると収支がプラス、つまり回収率が100%を超えてきます。
縦軸は収支ですので、期待値が高くなるにつれて購入点数が減少し、最終的に収支はゼロに収束します。
グラフが極大を迎える期待値を基準にして馬券を購入すれば良いのですが、実際のオッズが高くなるとこの期待値の基準も高くなることがわかりました。
そこで筆者は、実際のオッズに対して必要な期待値を表に記録して、その表を元にして馬券を購入するプログラムを組みました。
複勝の場合は以下の通りです。

単勝の場合と同様に、実際のオッズが高くなるとこの期待値の基準も高くなっています。
よって単勝の場合と同様に、実際のオッズに対して必要な期待値を表に記録しました。
このオッズと必要な期待値の表を見ながら、馬券を購入してやれば良いというわけです。
最適化した買い方での回収率の算出
先程作った表を元にして、残りの未使用のテストデータ(2020〜2021年分)を使用して、回収率を算出しました。
なおちゃんと購入点数も書いてあるので、収支を計算できるようにしています。
使用したコードは下記です。
結果、最初に述べた通り以下のようになりました。
単勝は1347点購入して回収率109%
複勝は710点購入して回収率113%
長くなりましたが以上がPythonを使用した競馬AIの作り方と回収率です。
おわりに
以上で競馬AIに関する解説を終了します。